Meeting the Dialogue Challenge
Posted by John Baez
.")
guest post by Dan Shiebler and Alexis Toumi
This is the fourth post in a series from the Adjoint School of Applied Category Theory 2019. We discuss Grammars as Parsers: Meeting the Dialogue Challenge (2006) by Matthew Purver, Ronnie Cann and Ruth Kempson as part of a group project on categorical methods for natural language dialogue.
Preliminary Warning: Misalignment in Dialogue
Traditional accounts of the mechanics of natural language have largely been focused on monologue and utterances in isolation: using formal languages and automata theory to characterise the set of grammatical or “well-formed” sentences. When faced with dialogue and informal conversation, this notion of grammaticality breaks down: people hesitate, correct themselves, interrupt each other, etc. In Toward a mechanistic psychology of dialogue (2004), Pickering and Garrod argue that dialogue represents a major challenge for psycholinguistics and give empirical evidence for interactive alignment as the psychological process underlying dialogue. We will aim at casting a categorical light on this dialogue challenge and on the computational model proposed by Purver, et al.
This computational linguistics article may look like the odd one out in the ACT reading list: it does not even mention category theory. Worse: the word “category” is actually used twice, but it doesn’t mean anything like a collection of arrows with composition; “adjunction” appears twice as well, but again nothing to do with pairs of functors and natural transformations. This is a typical example of a phenomenon psycholinguistics would call misalignment. If we imagine a dialogue between a linguist and a mathematician, they would use the same words to refer to different concepts, resulting in a failure of communication.
Context-Freeness and Monoidal Categories
It may now prove useful to give some historical context. In his Three models for the description of language (1956) and his monograph on Syntactic Structures (1957), Chomsky lays out a formal theory of natural language syntax with the context-free grammar (CFG) as its cornerstone. Formally, a CFG is given by a tuple where:
- and are two finite sets, called the vocabulary and the nonterminal symbols respectively.
- is a finite set of production rules and is the start symbol, where the Kleene star denotes the free monoid and denotes disjoint union.
A CFG generates a language where the rewriting relation is traditionally defined as the transitive closure of the following directed graph:
One may recast this into the language of monoidal categories by redefining where the transition relation is seen as a signature for the free monoidal category . That is, a string is grammatical whenever there exists an arrow from the start symbol to in . A typical arrow where may be encoded as a syntax tree:

A year later in The mathematics of sentence structure (1958), Lambek characterised the same context-free languages with his Lambek calculus, i.e. the internal language of biclosed monoidal categories. Half a century later in From Word To Sentence (2008), he simplified his formalism from biclosed to rigid monoidal categories and pregroup grammars. First introduced in Lambek (1997), pregroups are partially ordered monoids where every type has left and right adjoints, i.e. a pair of objects with two pairs of inequations:
Formally, a pregroup grammar is given by a tuple where:
- is a finite vocabulary, is a finite partially ordered set of basic types,
- is a finite relation called the dictionary or lexicon, where is the free pregroup generated by and is called the sentence type.
Again, we may define the language of as where now the dictionary is taken as a signature for the free rigid monoidal category . If we note that the generation and parsing problems form a duality where the output of the generation problem is the input to the parsing problem, we see that CFGs and pregroup grammars stand on opposite sides of this duality. That is, the start symbol is the domain of syntax trees while the sentence type is the codomain of pregroup reductions. The arrow encoding grammaticality is no more a tree but a planar diagram, e.g.:

Context-free grammars and pregroup grammars share the same expressive power, i.e. they generate the same class of context-free languages. However, they are only weakly equivalent, i.e. the translations between them preserve only grammaticality and forget the structure of the grammatical reductions, syntax trees or string diagrams. There is still open debate about the syntactic structure that underlies human language.
Thus, we may realign the terminology of the linguist and of the category theorist as follows: the “syntactic categories” of categorial grammars are really objects in some form of closed category and the “adjunctions” are really adjunctions after all! Indeed, while in CFGs an adjunct may be defined as a subtree which may be removed without affecting grammaticality, in pregroup grammars the same phenomenon is encoded as an adjunction, e.g. between the types of “furiously” and “sleep”.
Natural Language and Functorial Semantics
We argue that it is of interest to realign “syntactic categories” and “adjunctions” the other way round, i.e. take their category theoretic meaning and apply them to linguistics. Again we give some historical context by looking at two parallel uses of the word “universal”: universal algebra and Lawvere theories on one side, universal grammar and Montague semantics on the other.
In Adjointness in Foundations (1969), Lawvere lays out a program for the foundations of mathematics by characterising existential and universal quantification as left and right adjoints to substitution. In his doctoral dissertation Functorial Semantics of Algebraic Theories (1963), he defines what are now known as Lawvere theories and their models as monoidal functors where is the syntactic category encoding the theory: a monoidal category where the tensor is the categorical product and each object is isomorphic to a cartesian power for and some fixed .
The following year in English as a formal language (1970) and Universal Grammar (1970), Montague sets out to apply the same principle of compositionality to natural language. Recast using category theory, Montague semantics is a monoidal functor from the free monoidal category generated by the transition relation of a context-free grammar such that words are mapped to the singleton and the start symbol to a set of closed logical formulae. Explicitly, is given by a lambda term for each transition rule, mapping grammatical sentences to logical sentences in a compositional way, e.g.:
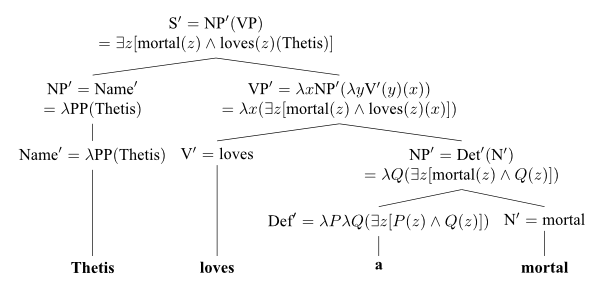
Even though the use of higher-order logic in Montague semantics suggests a connection with Lawvere theories through the internal language of topos theory, to the best of our knowledge Montague is as little known to category theorists as Lawvere is to linguists.
In the next section, we discuss a second principle at play in natural language semantics: distributionality, as summarised in Firth’s oft-cited maxim: “You shall know a word by the company it keeps”.
Categorical Compositional Distributional Models
How do we define a word’s company categorically? As a first approximation, we may take some large collection of sentences and look at the matrix encoding how many times each pair of words appeared together, i.e. for the indicator function of the utterance . Better approximations would be given by some renormalisation of this matrix such as TF-IDF or by information-theoretic measures like pointwise mutual information. The size of this matrix may be prohibitive and you may want to apply some dimensionality reduction to get some compressed encoding matrix for some hyper-parameter and some suitable semiring .
We give a very brief presentation of the categorical compositional distributional (DisCoCat) models of Clark et al. (2010), which were the topic of a previous post from the ACT 2018 seminar. DisCoCat models may be defined as monoidal functors where is the free rigid monoidal category generated by a pregroup dictionary and is the category of matrices over with Kronecker product as tensor. Note that the encoding matrix is precisely the data defining a monoidal functor such that for all , i.e. every word is of the same semantic type. In order to construct arbitrary DisCoCat models we need tensors of higher rank, e.g. the encoding of the verb will have dimension where we overload the notation for the noun type and the dimension of its image .
DisCoCat models valued in the category of finite sets and relations yield a truth-theoretic semantics for pregroup grammars in terms of conjunctive queries, the regular logic fragment of relational databases. Although much weaker than the higher-order logic of Montague semantics, conjunctive queries have nice complexity-theoretic as well as category-theoretic properties. Indeed, a celebrated theorem from Chandra, Merlin (1977) — conjunctive query evaluation is NP-complete — has recently been recast in terms of free cartesian bicategories in Bonchi et al. (2018): queries are arrows and evaluation reduces to the existence of 2-arrows. The significance of this result for natural language processing is discussed in De Felice et al. (2019), to appear in the ACT 2019 proceedings.
Both the relational models and the vector space models valued in yield some insight into the anatomy of word meanings through a common structure: the categories of matrices are all hypergraph categories, i.e. symmetric monoidal categories where each object is equipped with a special commutative Frobenius algebra in a coherent way. This allows us to model information flow and give a semantics to those functional words which appear in almost every context, hence for which distributionality gives practically no information content: auxiliary verbs such as “does”, coordinators e.g. “and” and “or”, relative and personal pronouns e.g. “that” and “them” — see the line of work by Sadrzadeh, Coecke and others [1, 2, 3, 4, 5].
As we discuss in the next section, Frobenius algebras can even be used to give a meaning to words that are missing, see Wijnolds, Sadrzadeh (2019).
Contextual Grammaticality with Dynamic Syntax
Dynamic Syntax, which emerged from work by Kempson et al., is based on a third linguistics principle, incrementality: in dialogue people speak and listen to only one word at a time. Modelling language generation and parsing as linear-time processes has two related justifications: on the computational side it allows to implement real-time applications like personal assistants; on the cognitive side there is empirical evidence that human parsing is largely incremental, see e.g. Philips, Linear Order and Constituency (2003).
Dynamic syntax (DS) takes a semantics-driven approach to grammaticality: a sequence of words is defined as grammatical precisely if it can be given a semantics in the model. DS replaces the lambda terms of Montague semantics by a set of semantic trees based on Hilbert’s epsilon calculus, with the initial empty tree and a subset of completed trees, i.e. closed logical formulae. In our following discussion of DS we use and to represent the tree operators on logical types and logical formulae respectively.
DS also defines a set of actions, specified in an imperative programming language based the logic of finite trees of Blackburn et al. (1994). A DS lexicon is then given by a function assigning a lexical action to each word in the vocabulary , e.g.

DS semantic trees are annotated with some further structure: pointers, metavariables and requirements, as illustrated in the following example.
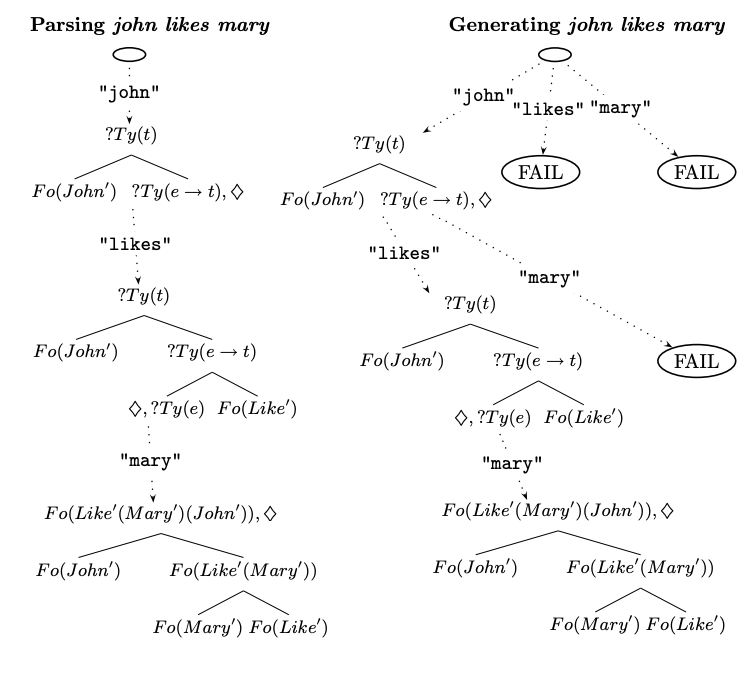
- Pointers: The semantic trees are equipped with a pointer and actions may be specified locally to that pointer in terms of descendants and ancestors in the tree.
- Metavariables: Metavariables are underspecified terms. They include relative pronouns such as “he” or “she” as well as subjects with indefinite scope like the word “someone” in the sentence “Everyone likes someone.”
- Requirements: After parsing the subsentence “John likes”, the semantic tree will include a requirement for an argument type (represented by in the figure above). This requirement will be filled when the parser reaches the next word, “Mary”, which will yield the complete tree for the sentence “John likes Mary.”
In Grammars as Parsers (2006), Purver et al. argue that incrementality is key if we are to model the language of informal conversations. They apply dynamic syntax to the following phenomena, which are all problematic in traditional approaches to language processing:
- Ellipses: in informal conversations, context allows participants to omit words from sentences without affecting their meaning, e.g. A: “Mary studies categories.” B: “John does too.”
- Routinization: the repetition of the same ambiguous phrase (“that guy”) resolves the ambiguity and makes participants more likely to answer using the same phrase again.
- Shared utterances: participants may complete each others’ sentences, e.g. A: “John likes…” B: “category theory? I know.”
For example, consider the dialogue A:”Mary upset Sue.” B:”John did too.” When parsing “John did too,” the DS parser will represent “did too” as a requirement asking for what John did. If the semantic tree encoding context contains a node of the appropriate type (e.g. ), the parser may use this to fill the requirement.
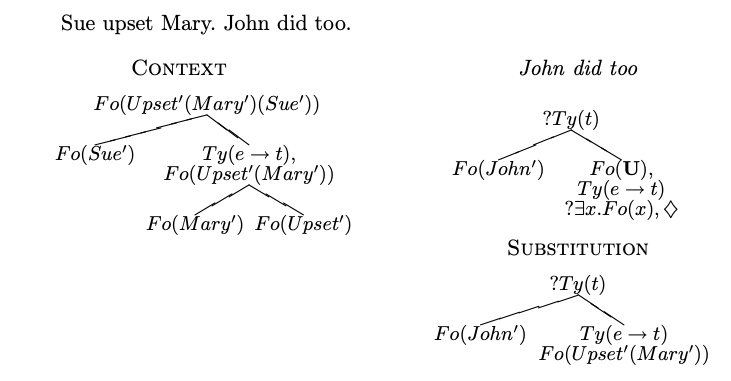
Furthermore, Purver et al. model the interactive alignment of Pickering and Garrod on three levels: lexical i.e. participants re-using the same words, syntactic i.e. participants re-using the same phrase structure, and semantic i.e. participants converging to the same representation of the situation. This requires a notion of state that goes beyond that of isolated sentences: we need to encode the participants’ memory of the dialogue’s history. The state of a DS parser — also called the context — is given by a sequence of triples , such that for all and , i.e. we record the list of actions which are constructed from the utterance . Next to lexical actions, DS defines a set of computational actions which may depend on context, e.g.

We say a context is valid if for all we have is a completed tree. This model defines a notion of contextual grammaticality: whether an utterance is well-formed may depend on what has been said before. When the system has only a single speaker, we can represent this context with the history string . Below we illustrate several subcases of this single speaker system. A string is:
- fully grammatical if it is parsable from any valid context e.g. “John went to the market”,
- fully ungrammatical if there is no context in which it is parsable e.g. “John market”,
- well-formed if there is some valid context in which it is parsable e.g. “He went to the market”,
- potentially well-formed if there is some context (not necessarily valid) in which it is parsable e.g. “the market”.
Bringing it All Together: DisCoCat Inc.
The aim of our summer project is to incorporate the incremental insights from dynamic syntax into categorical compositional distributional models, DisCoCat Inc. Sadrzadeh et al. (2018) explore the first steps in this direction, mapping semantic trees to tensor networks and actions to tensor contraction.
In conclusion, we may attempt to reformulate the dialogue challenge in categorical terms: given DisCoCat models and , encoding the language of Alice and Bob respectively, can we build a new model giving a semantics to the dialogues between them? Furthermore, can we make the model for this common language incremental, and account for the real-time dynamics of dialogues? These questions inspired a number of links with the other group projects of the ACT adjoint school:
- Partial evaluation and the bar construction: Can we make use of monads, partial evaluations and rewriting theory (as discussed in a previous guest post) to model the dynamics of syntactic structures and unify universal grammar with universal algebra?
- Toward a mathematical foundation for autopoeisis: Can we model natural language entailment and question answering using the graphical regular logic of Fong, Spivak (2018)? Can we investigate language as an autopoeitic system through the behavioral mereology of Fong et al. (2018)?
- Simplifying quantum circuits using the ZX-calculus: Can we use techniques inspired from quantum circuit minimisation (discussed in two previous posts here and there) to perform summarisation, i.e. find the shortest text which encodes the semantics of a given dialogue?
- Traversal optics and profunctors: the theory of lenses has recently been used to model both learning algorithms in Fong, Johnson (2019) and Wittgenstein’s language games in Hedges, Lewis (2018), can we use these insights and the categorical view of optics developed in Milewski (2007) to model natural language learning through dialogue?
Re: Meeting the Dialogue Challenge
This may not be as off-topic as it appears at first sight. The following, by
https://en.wikipedia.org/wiki/Cosma_Shalizi
http://bactra.org/weblog/algae-2018-08.html
seems to me an interesting example (of what, I’m not so sure) that deserves to be better known:
==========================
Books to Read While the Algae Grow in Your Fur, August 2018
Vladimir I. Propp, Morphology of the Folktale [as Morfologija skazki, Leningrad, 1928; translated by Svatava Pirkova-Jakobson, Indiana University Press, 1958; second edition, revised …
I’d known this book for quite some time, and browsed in it long ago, but never actually read it until this year. It’s a really incredible piece of work.
Propp set out to identify the basic elements of the plots of Russian fairy tales, working at a level of abstraction where “it does not matter whether a dragon kidnaps a princess or whether a devil makes off with either a priest’s or a peasant’s daughter”. He came up with 31 such “functions”. Justlisting them (chapter 3) has a certain folkloric quality…
What I find so astonishing here is that , though propounded many years before that notion emerged in linguistics, logic and computer science. Specifically, it is a formal grammar which generates fairytale plots. Propp realized this, and used the schema to create new fairy tales…
It’s especially noteworthy to me that Propp’s schema is a grammar, i.e., at the lowest level of the Chomsky hierarchy. These correspondto the regular expressions familiar to programmers, to finite-state machines, and to (functions of) Markov chains. The production rules would be something like …
… To sum up, Propp did grammatical induction on fairytales by hand, in 1928, and came up with a regular language.