Coalgebraic Behavioural Metrics: Part 1
Posted by Emily Riehl
.")
guest post by Keri D’Angelo, Johanna Maria Kirss and Matina Najafi and Wojtek Rozowski
Long ago, coalgebras of all kinds lived together: deterministic and nondeterministic automata, transition systems of the labelled and probabilistic varieties, finite and infinite streams, and any other arrows for an arbitrary endofunctor .
These different systems were governed by a unifying theory of -coalgebra which allowed them to understand each other in their differences and become stronger by a sense of sameness all at once.

However, the land of coalgebra was ruled by a rigid principle. Its name was Behavioural Equivalence, and many felt it was too harsh in its judgement.

Some more delicate transition systems like the probabilistic kinds, found being governed by behavioural equivalence to be unjust towards their nuanced and minute differences, and slowly, diversion began to brew among the peoples.
More and more did the coalgebra find within themselves small distinctions that did not quite outweigh their similarities, and more and more did they feel called to be able to express that in their measurements. The need for a notion of behavioural distance gained momentum, but various paths towards a behavioural distance emerged.
Transition systems as coalgebras
State transition systems are a pervasive object in theoretical computer science. Consider a deterministic finite automaton. The usual textbook definition (see, for example, “Automata and Computability” by Dexter Kozen) of a DFA is a 5-tuple consisting of finite set of states , an alphabet , a transition function , that when given a state and a letter , yields a state that can be obtained by reading a letter from the alphabet in some state . The subset describes a set of states which are accepting and denotes the initial state. The set of words over an alphabet , which we denote by is the least set satisfying the following
We can now extend the transition function to operate on words. Define by induction, using the construction of a word:
A word is accepted by the automaton if . The set of all accepted words is called the language of an automaton. The languages that can be accepted by a deterministic automaton with finitely many states are called regular or rational languages.
Now, let’s slightly relax and rearrange the definitions.
First, let’s drop the idea having an initial state. Instead of the language of the automaton, we will now speak of a language of a state of an automaton. Every automaton induces a function which is given by , and the set is called the language of the state .
We can view the set of accepting states, as a function to the two-element set, such that . Currying the transition function yields . Now, we can use cartesian product and combine the functions and into a function . Intuitively, such function takes a state to its one-step observable behaviour. Finally, we will drop the requirement of the set of states to be finite. Automata with infinitely many states can denote more expressive langauges from the Chomsky hierarchy, such as Context-Free Languages.
Each deterministic automaton can be now viewed as a pair . More interestingly, we can endow the set of all languages with the structure of a deterministic automaton. Define the acceptance function to be given by . In other words, a language will be an accepting state if and only if it contains the empty word. Now, define a transition function to be given by . Intuitively given a language and a letter , we transition to a language obtained by cutting that letter from words that start with in the original language. The transition structure is often called the semantic Brzozowski derivative, and the automaton is called the (semantic) Brzozowski automaton.
It can be observed that the Brzozowski automaton provides a form of a universal automaton in which every other deterministic automaton embeds in a well-behaved way. By well-behaved, we mean the following: - if a state in some automaton accepts, then its language contains an empty word, and so the language is an accepting state in the Brzozowski automaton, - if a state transitions to an another state on some letter , then in the Brzozowski automaton, the language of the first state transitions to the language of the second state on the same letter .
Formally speaking, let be a deterministic automaton with being the set of states. The function taking each state to its language satisfies the following for all : - , - for all , .
In other words, the map to the Brzozowski automaton is structure-preserving. More generally, functions between any two deterministic automata satisfying the condition above are called homomorphisms. One can easily show that the Brzozowski automaton satisfies a certain universal property, namely that every other deterministic automaton admits a unique homomorphism to it (which is precisely the map which assigns to a state its language). We can use the Brzozowski automaton and language-assigining map to talk about the behaviour of states – we will say that two states are behaviourally equivalent if they are mapped to the same language in the Brzozowski automaton.
To sum up, the set of languages equipped with an automaton structure provides a universal and fully abstract treatment of the behaviours of states of deterministic automata.
Now, consider a different object of study within theoretical computer science and logic: Kripke frames. The usual way one gives the semantics of modal logic is through Kripke frames. A Kripke frame is a pair consisting of a set of worlds and an accessibility relation . A valuation is a function, which assigns to each world a set of atomic propositions which are true in it. A Kripke frame along with a valuation forms a Kripke model. Given two Kripke models and , we call a map a -morphism if the following conditions hold: - if , then , - if for some , then and for some , - if and only if . domae -morphisms are well-behaved morphisms preserving the structure of Kripke models (and hence the validity of modal formulae), and are thus somewhat similar in spirit to the homomorphisms between deterministic automata.
Observe that an accessibility relation on a set of worlds can be viewed equivalently as a function . Similarly to deterministic automata, we can use the Cartesian product to combine seuthe accessibility relation and the valuation in a frame into a function which takes a world to its one-step observable behaviour. A Kripke model then becomes a pair .
Both deterministic automata and Kripke frames are pairs consisting of a set of states, and a one-step transition function which takes a state into some set-theoretic construction describing its bservable behaviour. These set-theoretic constructions are endofunctors , in our case and . Deterministic automata and Kripke frames are concrete instances of coalgebras for an endofunctor.
Let’s spell out the concrete definitions.
Let be an endofunctor on some category. An -coalgebra is a pair consisting of an object of category and an arrow .
A homomorphism from -coalgebra to is a map satisfying . Homomorphisms of deterministic automata and -morphisms are the concrete instatiations of this definition.
Coalgebras and their homomorphisms form a category. Under an approriate size restrictions on the functor , there exists a final coalgebra , which is a final object in the category of coalgebras. In other words, it satisfies the universal property that for every -coalgebra there exists a unique homomorphism . Final coalgebras provide a abstract domain providing denotation of the behaviour of -coalgebras. We already saw that in the case of deterministic automata, Brzozowski automaton provided a final coalgebra, where formal langauges denoted the behaviour of states of automata. Finally, the concrete notion of behavioural equivalence was given by language equivalence.
Behavioural equivalence of quantitative systems
Having introduced the motivation for the study of coalgebras, we move on to a particular example, which will motivate looking at behavioural distance. Consider an endofunctor , which takes each set to the set of discrete probability distributions over . On arrows , we have that is given by , also known as the pushforward measure. Coalgebras for are precisely Discrete Time Markov chains. Since all the states in such a case have no extra observable behaviour besides the transition probability, it turns out that all the states are behaviourally equivalent. Let’s consider a slightly more involved example, where each state can also be terminating with some probability.
Consider a composite functor that takes a set to . Coalgebras for it can be thought of Markov Chains with potential deadlock behaviour. Now, let’s look at a concrete example of a four state automaton
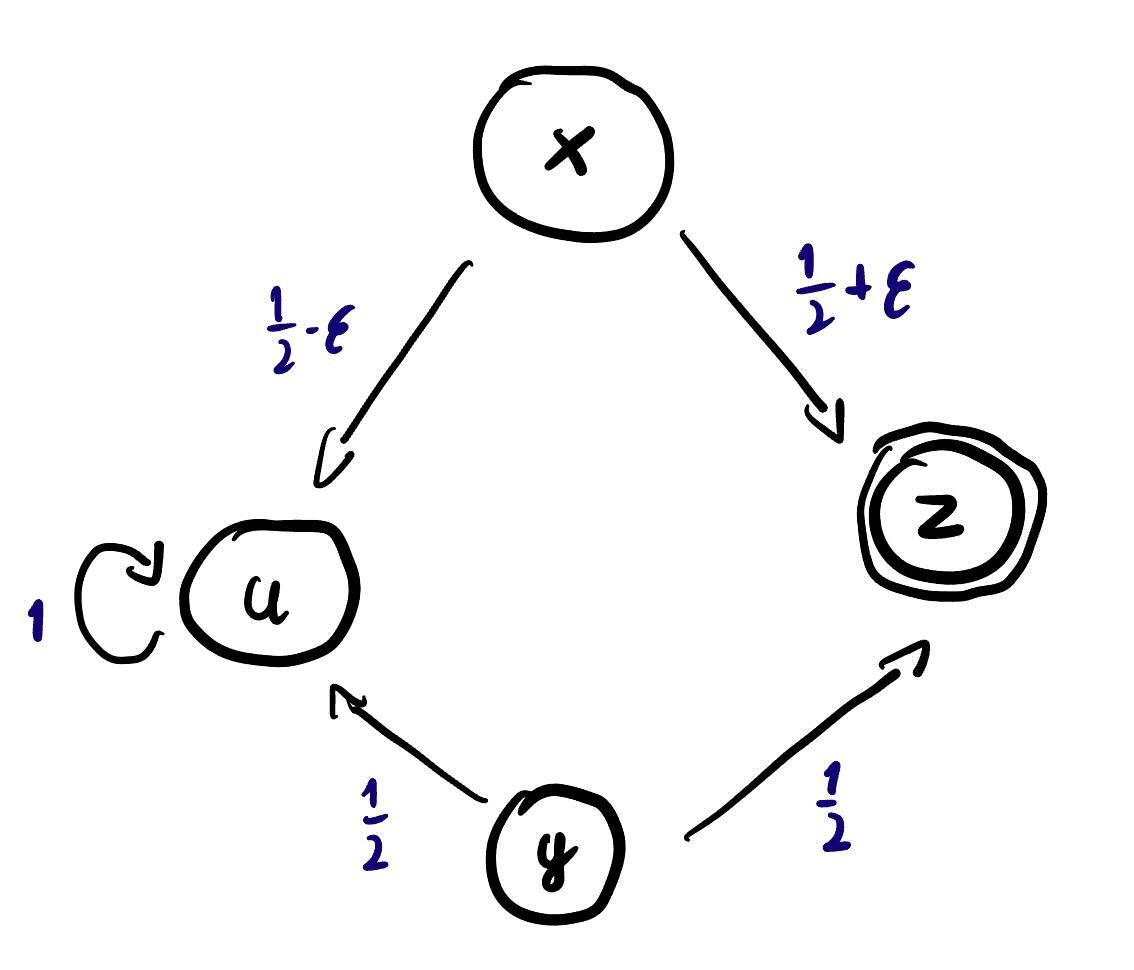
State enters deadlock with probability , while state has a self loop with probability . The functor admits a final coalgebra and it is not too hard to observe that states and exhibit completely different behaviour and will be mapped into distinct elements of the carrier of final coalgebra. State has probability of ending in and probability of ending in . It has two equiprobable options of tranisitioning to states, which behave in a different way from eachother. It is not too hard that is also not behaviourally equivalent to and . Finally, consider the state . Let . State can transition to with probability and transition to with probability . Observe that only when state is behaviourally equivalent to . Even for very small non-zero values of , states and would be considered inequivalent.
For practical purposes, coalgebraic behavioural equivalence (for coalgebras on ) might be way too restrictive. In the case of systems exposing quantitative effects, it would be more desirable to consider a more robust notion of behavioural distance, which would quantify how similarly two states behave. The abstract idea of distance has been captured by mathematical notion of metric spaces and related objects.
Pseudometrics and
Underlying the behavioural distance between states of a coalgebra is the mathematical idea of distance. Most commonly, distance is treated in the form of a metric space. A metric space is a set with a distance function that satisfies the following axioms for each . - Separation: . - Symmetry: , - Triangle inequality: .
In the context of coalgebras, however, we may wish to have a slightly altered notion of distance to capture behavioural similarity.
If two states behave identically, then even if they are not the same state, we expect their distance to be zero. Thus, we relax the separation axiom and only require that for all . This yields a pseudometric. Note that a pseudometric is still symmetric and still fulfills the triangle inequality. It is also possible to have an asymmetric notion of distance, where both separation and symmetry are relaxed. The distance function obtained like that is a function that only fulfills the triangle inequality, but it is possible that and for some . This is called a hemimetric, and it occurs when formalising distance via fuzzy lax extensions.
Finally, we may wish to bound the distance, to have a way of expressing when two states are “maximally different”. For example, we use this to express that an accepting and a non-accepting state are maximally different. In order to accommodate that, we instead define the distance function as , where . In the context of behavioural distances on coalgebra, it is common to take or . However, in the case of , this requires a way of calculating with infinity, and this is resolved by defining distance and addition with infinity as
Once we fix the bound and some set , we can consider the set of all pseudometrics over . It turns out that under the pointwise order and appropriate definitions of meet and join, becomes a lattice. In particular, the order is given by and for a subset ,
Moreover, it is a complete lattice, meaning each subset has a meet and a join. The lattice being complete implies that the category of all pseudometric spaces for a fixed is complete and cocomplete, which in turn implies that the category has products and coproducts.
Here’s how we define this category of pseudometric spaces:
The category for a fixed has - pseudometric spaces as objects, - nonexpansive maps as morphisms.
The definition of nonexpansive maps is quite immediate: i.e. the maps do not increase distances between elements. Clearly, the composition of nonexpansive maps is nonexpansive as well, and the identity map is nonexpansive.
Motivation from transportation theory
In the long run, we would like to be able to go from distances on the states of coalgebra to distances on observable behaviours. For now, let’s focus our attention on the discrete distributions functor. Let be a set equipped with a -pseudometric structure on it, given by and let’s say we have two distributions . We would like define a pseudometric structure which would allow us to calculate the distance between and .
It turns out, there is well-known answer to this question, coming from the field of transportation theory. Let’s make the example slightly more concrete. Let and from now on we will omit the subscript on the map
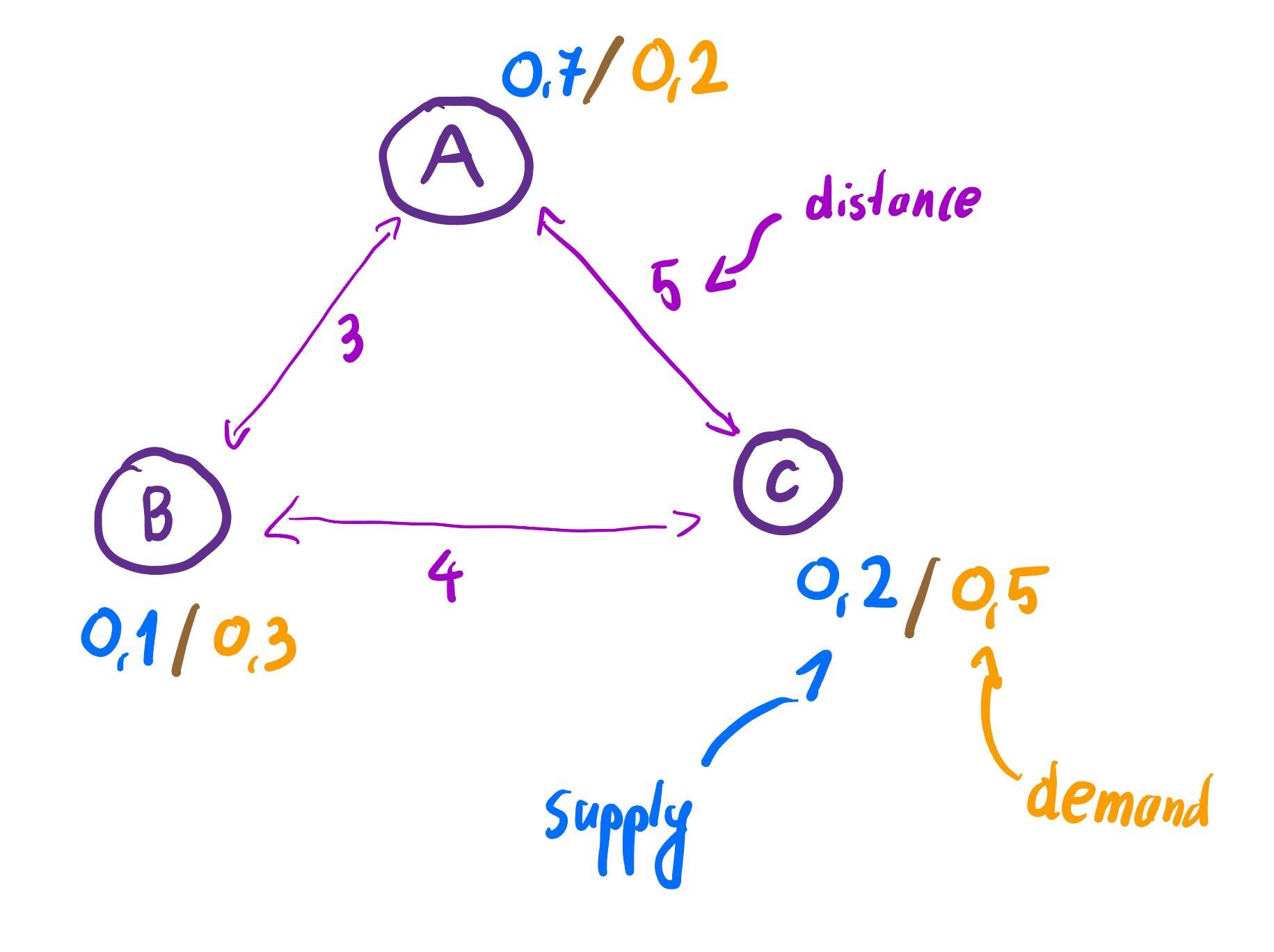
Imagine that and are three bakeries with an adjacent shop where one can taste the pastries. We have that . Moreover, let’s say that distance between and is three (), while and are in distance four () and and are in distance five (). Hence, is a metric space.
Let be the distribution of supply of the pastries in each of the bakeries. , and
Let be the distribution of demand in pastry shops adjactent by the bakeries. We have that , and .
In bakery , there are more pastries produced than being consumed, while in more people are having their pastry than can actually produce. The reasonable thing to do for an owner of these places, would be to redistribute the pastries so the needs of customers are satisfied. One way of solving this problem would be to come up with a transport plan, a map , where would intuitively mean move the ratio of pastries from bakery to . Such a transport plan should satisfy
- For all , - whole supply of pastries is used
- For all , - all demand is satisfied
In other words, one can think of as a joint probability distribution which can be marginalised into and . Such a joint distribution, which equivalently describes a transportation plan is called a coupling of and . There can be multiple transportation plans, but some might involve unnecessary movement of pastries to the bakery which is too far away. Each transportation plan can be assigned a cost, proportional to the distance that each fraction of pastries needs to travel. The cost of plan is given by defined as
Let denote the set of all couplings of and . The owner of the bakeries is aiming to minimise the total cost of transportation. The minimal cost of the tranportation from to is given by the following
It turns out that phrasing this minimisation problem as a linear program guarantees existence of the optimal coupling, which costs the least. The definition above actually defines takes a pseudometric and transforms it into a pseudometric on distributions over . This (pseudo)metric is known as Wasserstein metric.
In our example, it turns out that the most cost optimal plan is to do the following: - Move of pastries from (where there is an overproduction) to - Move of pastries from (where there is an overproduction) to
The optimal cost is given by the following
Now, consider an alternative approach. Let’s say that instead of organising transport on their own, the owner of the bakery will hire an external company to do that. In such a setting the company will assign to each bakery a price for which it buy pastries (in case of overproduction) or sells (in the case of higher demand). Formally it will be modelled as functions satisfying that for all , we have that One can think of the requirement above that intuitively owner of the bakeries won’t accept situation when they have to pay more for the transport than when performing the transport on their own. Formally speaking, it means that is a nonexpansive function from to nonnegative reals equipped with euclidean norm . Given a price plan the income of the company will be given by
The external company would like to maximise their profits, so the optimal profit would be given by
The optimal pricing plan exists (again by formulation of the problem as the linear programming problem), so the above is well-defined. happens to be a pseudometric, as long as is. This notation of distance between distributions is known as Kantorovich metric.
For the example above, the optimal price plan is given by the following: - Owner of the bakeries gives out the excess from for free () - Bakery buys necessary pastries for three monetary units () - Bakery does the same with the cost of five units () In such a case, the distance is given by the following
In this particular case, we ended up with the same distance as before, when talking about transport plans. It is no coindidence and actually an instance of the quite famous result, know as Kantorovich-Rubinstein duality. We have that One can intuitively think that minimising the transportation cost is dual to the external company trying to maximise their profit.
Liftings to
The above distances can also be thought of as answers to the following lifting problem. If is a functor on , then how can one construct a functor on such that
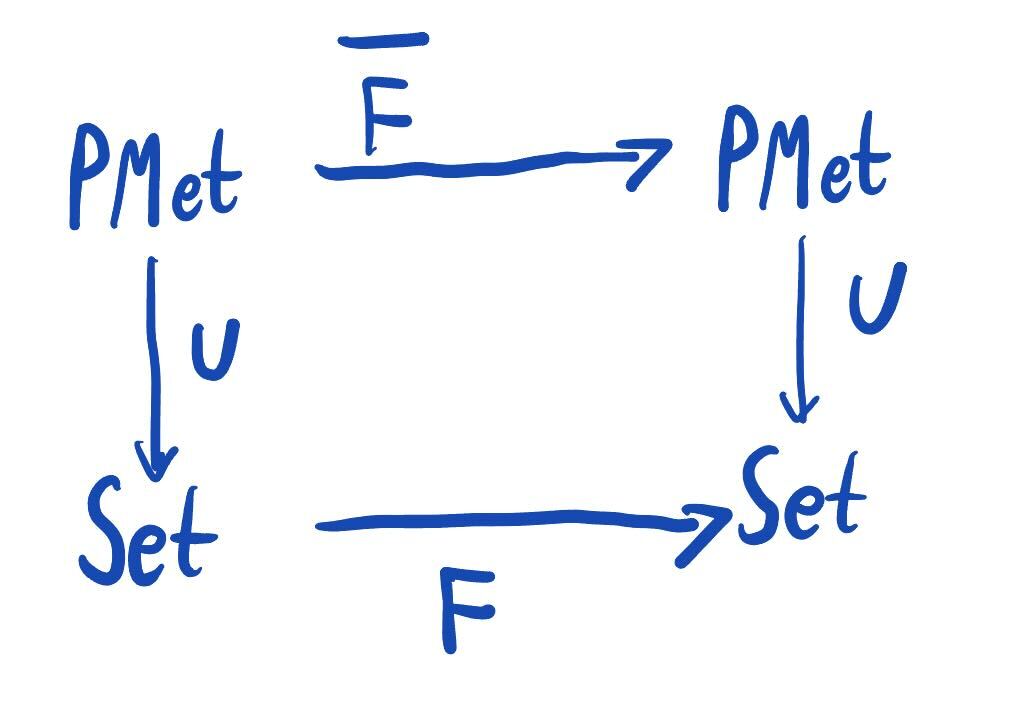
commutes? In other words, how can we construct a functor that acts as on the underlying sets and nonexpansive functions?
The first priority when defining a lift is that should be a functor. That is, when given a pseudometric space , we need to define a pseudometric on in a sensible way. Since the definition of a lift implies that is just for all nonexpansive and we need to be nonexpansive, then the pseudometrics on the objects and need to ensure that is nonexpansive. Then and only then does become a functor.
Put precisely, in order to have a lift, we require that - for any pseudometric space , we have a pseudometric space such that - for any nonexpansive functions , the function and is nonexpansive.
In the above case of the distance between two distributions, an initial distance between elements of was given, and the distance on was defined. The functoriality of such a construction was not checked, but it holds (and the proof in the abstract case can be found in the referential paper).
Inspired by the constructions in the case of , Kantorovich and Wasserstein liftings can be defined for arbitrary functors. This is also where the relevance to coalgebras becomes evident – the notion of a lift enables us to start with a pseudometric on the state space , and induce from that a pseudometric on the space of possible behaviours .
In the mechanics of lifting a pseudometric, it is useful to consider an evaluation function: a function for all objects . Then, we can consider the function defined as for morphisms . Certain choices of evaluation functions may arise in the case of particular functors. For example, in the case of , the evaluation function is taken to be the expected value .
Kantorovich lifting
The Kantorovich lifting is defined as follows. Let be a functor on with an evaluation function . Then the Kantorovich lifting is the functor that takes to the space , where
This is in fact the smallest possible pseudometric that makes all functions nonexpansive. The Kantorovich lifting preserves isometries.
Wasserstein lifting
The Wasserstein distance that is required to define the Wasserstein lifting, needs more work to set up. Altogether, it requires a generalised definition of couplings, some well-behavedness conditions from the evaluation function, and the preservation of weak pullbacks from the functor.
Re: Coalgebraic behavioural metrics - Part 1
I didn’t see any references or links in this post. Did they get eaten during the posting process?